近日,公司特聘副研究员任昊、助理研究员刘翱以第一作者完成的3篇研究成果入选人工智能顶级会议AAAI 2025。AAAI全称为人工智能促进会(Association for the Advancement of Artificial Intelligence),是人工智能领域的主要国际学术组织,该协会主办的AAAI年会(AAAI Conference on Artificial Intelligence)是国际顶级人工智能学术会议之一,被中国计算机学会评定为A类学术会议(CCF-A)。
3篇研究成果分别涉及到人工智能安全、模型安全推理等人工智能相关领域。以下是论文的简要介绍:
1、PrivDNFIS: Privacy-preserving and Efficient Deep Neuro-Fuzzy Inference System
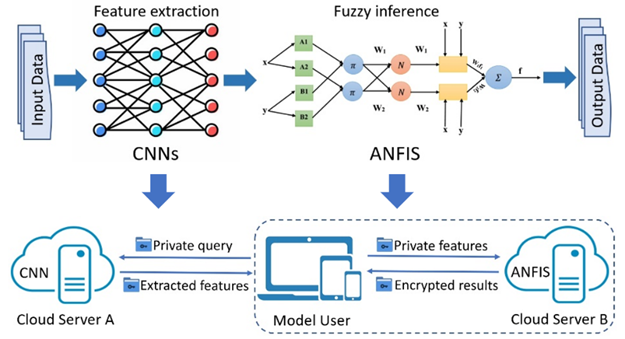
深度神经网络(DNNs)在图像识别、自然语言处理、医学诊断等领域成果显著,但因其数十亿连接权重的复杂性,理解和信任成为难题,可解释人工智能模型应运而生。深度神经模糊推理系统(DNFIS)融合深度学习的模式识别与模糊逻辑的可解释性,能实现精确透明决策,在医疗、法律等领域优势突出,还借助规则表示和直观语言变量确保清晰性,展现出高性能。然而从数据安全角度看,当用户向第三方模型所有者发送推理请求时,数据传输存在被窃取或篡改风险,如医疗诊断场景中,用户上传的敏感健康数据在传输和存储时,若防护措施不到位,就可能因黑客攻击、内部人员违规操作等导致数据泄露,严重威胁个人隐私和数据安全。强化DNFIS这类模型推理服务的数据安全防护,在数据传输加密、密文域推理等方面采取有效措施,具有现实需求。因此,本文提出了名为PrivDNFIS的方案。
构建适用于深度神经模糊推理系统(DNFIS)的安全推理方案存在诸多技术挑战,而 PrivDNFIS 在应对这些挑战方面做出了多个具体贡献。从技术挑战来看,一方面,要深入研究 DNFIS 网络架构及其神经元内部结构来明确计算任务,且当前缺乏适应模糊隶属函数的安全计算协议,这就需要对 DNFIS 和密码技术展开研究;另一方面,保护用户输入数据安全需要理论保障,在给定威胁模型下确保语义安全性是项具有挑战性的任务,同时当复杂推理函数和可证明安全性成为基本要求时,降低计算开销也颇具难度。面对这些挑战,PrivDNFIS 开启了为 DNFIS 设计安全推理方案的研究,通过利用基于RLWE的同态加密和密文提取技术,提出了安全高效的推理方案;还在半诚实威胁模型下,为方案提供了正式的安全证明,分析合理简洁;并且对所用到的基础协议包括安全聚合和向量内积等提出了多项优化方案,省去了繁重的同态密文旋转操作。调整现有DNFIS 模型的多个算子,在不影响准确性的前提下,使端到端时间开销相对于基准方案降低了1.9到4.4倍。
公司特聘副研究员任昊为文章第一作者,副研究员兰晓为第二作者,第一通信作者为陈兴蜀教授,第二通信作者为唐瑞助理研究员。该成果完成单位为JBO竞博官网(研究院)、数据安全防护与智能治理教育部重点实验室。
2、Grimm: A Plug-and-Play Perturbation Rectifier for Graph Neural Networks Defending against Poisoning Attacks
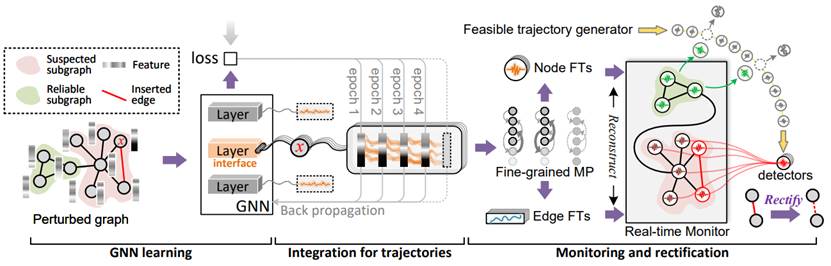
人工智能的重要工具图神经网络(GNN)在节点分类、推荐系统等领域有着广泛应用,如何应对针对GNN的恶意攻击成为了亟待解决的挑战。特别是图中微小的结构性变化,如插入或删除边,可能导致模型的严重误判,这类“中毒攻击”对GNN的安全性构成了极大威胁。目前,许多防御方法虽然能增强GNN的鲁棒性,但往往需要完全替换原有的模型架构,这不仅增加了计算负担,还可能导致性能损失,无法充分发挥GNN的优势。因此,开发一种既能保证模型安全性,又能保持其原有性能的防御机制显得尤为重要。
针对这一问题,本研究提出了图神经网络免疫系统(GRIMM),这是首个“即插即用”的防御方法,能够在不改变原有GNN架构的基础上,有效防止中毒攻击。与传统的防御机制不同,GRIMM通过监控GNN训练过程中的特征轨迹,实时检测和修复图中出现的对抗性边,确保GNN能够在正常训练的同时,抵御恶意攻击。该模型的创新之处在于,它将生物免疫系统的工作原理应用于图神经网络,利用特征轨迹的异常变化来识别并修正攻击,同时保障防御过程的独立性和并行性,不会干扰GNN的训练和优化。GRIMM不仅能够与主流GNN模型(如GCN、GAT和GraphSAGE)兼容,还具备良好的可转移性,能够在不同系统之间共享检测器,大幅提升修复效率。实验结果表明,GRIMM在多个真实数据集上表现优异,显著提高了GNN在恶意攻击下的分类准确性,同时减少了计算开销,尤其在大规模图数据集上展现了可喜的效率。
公司助理研究员刘翱为文章第一作者。该成果完成单位包括JBO竞博、华中科技大学和成都信息工程大学,JBO竞博官网是该成果的第一单位。
3、Graph Agent Network: Empowering Nodes with Inference Capabilities for Adversarial Resilience
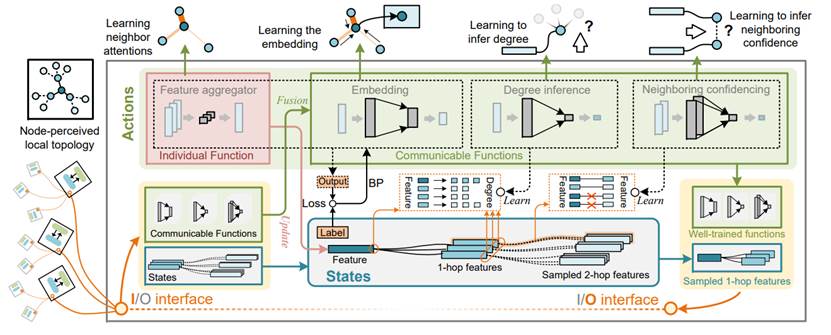
人工智能的重要工具图神经网络(GNN)在节点分类、推荐系统等领域有着广泛应用,如何应对针对GNN的恶意攻击成为了亟待解决的挑战。传统的GNN模型采用端到端的全局优化训练方法,虽然能够高效地完成任务,但也使得模型暴露出对抗性边扰动的安全隐患,攻击者能够通过微小的结构性修改来误导分类结果,进而破坏系统的安全性。现有的防御方法往往仍依赖于全局优化训练,面对自适应攻击(Adaptive Attacks)依然是脆弱的,无法有效应对更复杂的攻击场景。
针对这一挑战,本研究提出了图智能体网络(GAgN),这是首个通过去中心化智能体机制来增强节点自主推理能力的图神经网络防御模型。与传统防御模型依赖全局优化的方式不同,GAgN赋予每个节点独立的1跳邻居视野,通过去中心化的智能体间交互,节点能够逐步获得整个网络的全局信息,从而有效识别并过滤对抗性边。GAgN的设计理念源自自然界中的去中心化智能,防止恶意信息的全局传播,抵御基于全局优化的二次攻击。GAgN不仅能够有效提升节点分类精度,且具有较强的对抗性边过滤能力,实验结果表明,与目前最先进的防御方法相比,GAgN在面对扰动数据集时的分类准确率表现最佳。此外,GAgN的计算复杂度得到了显著降低,通过理论证明,GAgN仅需要单层的感知机(MLP)即可实现任务的完成,从而极大地提高了模型的效率。实验结果也显示,GAgN能够有效防止自适应攻击,即使在全局训练接口被关闭的情况下,依然能够保持对抗性鲁棒性,确保安全性和性能的平衡。
公司助理研究员刘翱为文章第一作者。该成果完成单位包括JBO竞博、天津大学、华中科技大学和成都信息工程大学,JBO竞博官网是该成果的第一单位。
作者简介:
任昊,博士,特聘副研究员,主要研究领域为AI安全和隐私保护,高级网络威胁检测,应用密码学。长期担任IEEE TIFS、IEEE TDSC等安全领域CCF-A类期刊审稿人以及IEEE ICC、IEEE Globecom、KSEM等国际会议的PC member。成果主要发表于CCF-A类会议WWW、AAAI,CCF-A类期刊IEEE TIFS, IEEE TDSC等。
刘翱,博士,助理研究员,主要研究领域为人工智能安全,包括AI对抗攻击和防御、AI可解释性和AI隐私保护。长期担任CPVR、ICCV、ECCV、AAAI、IEEE TNNLS等国际会议或期刊的PC member/Reviewer,成果获UC Riverside、Purdue、UIUC、NTU、USYD、UIC、Sony、悉尼大学、中科院计算所、中科院信工所等国内外知名高校/企业的正面评价和引用。


 当前位置:
当前位置: